Watch out for that Distribution Database
I received some pretty serious alerts this morning about our database server running low on disk space and quickly discovered something amiss:
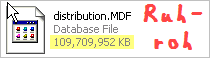
That’s a tad higher than usual…just 100x bigger than it should be (yikes)! Allow me to illustrate how I imagine the last few months going for this gargantuan file:
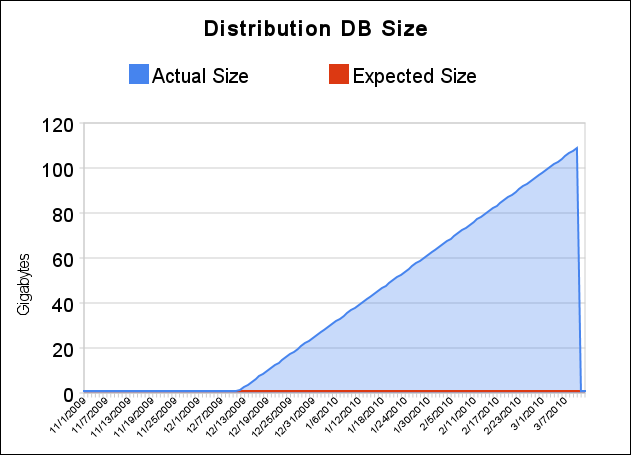
The problem turned out to be that several of the replication SQL jobs were disabled (since…months ago). The pertinent job is probably this one, the distribution clean up job:
![]()
It’s supposed to run every 10 minutes to tidy things up in the distribution database. I guess not running for three months could lead to some problems (eek!). There’s really no excuse for this—it’s embarrassing. I’m not the DBA for this system but I should have noticed; a lot of people should have noticed.
Since this task was disabled (not failing), it didn’t show up in our usual alert stream. I’m not sure how we solve that problem other than create an alert that detects disabled jobs. Or better yet, we could create alerts that fire whenever the job hasn’t run in the last n minutes—something like that.
Of course adding more sensitive alerts to the sizes of certain files or the free space of certain drives will help, too.
So I guess the lesson here is to run regular checkups on your critical infrastructure and leverage monitoring services if you can to make the checkups easier and more effective.