Make way for a unique key constraint by renaming/updating duplicate rows in SQL Server
If you want to add a unique key constraint or index to a table that might have duplicate records you’re in for some fun. You can either delete the duplicates, or fix the data to make them unique.
Suppose you have a table “Widgets”, which should be unique on SupplierId and Name, but isn’t. This tsql script will update the duplicates by appending a “(1)”, “(2)”, etc. to the Name, thus satisfying the proposed UKC:
DECLARE @Widgets TABLE(
Id INT NOT NULL PRIMARY KEY,
SupplierId INT NOT NULL,
Name NVARCHAR(50) NOT NULL)
INSERT INTO @Widgets (Id, SupplierId, Name)
VALUES (1, 1, 'WidgetA'),
(2, 2, 'WidgetA'),
(3, 3, 'WidgetB'),
(4, 3, 'WidgetB'),
(5, 3, 'WidgetC'),
(6, 3, 'WidgetC'),
(7, 3, 'WidgetC')
SELECT * FROM @Widgets
;WITH cte AS
(
SELECT
ROW_NUMBER() OVER(PARTITION BY SupplierId, Name ORDER BY Id) AS rno,
Name
FROM @Widgets
)
UPDATE cte SET Name = Name + ' (' + CONVERT(varchar(10), rno) + ')'
WHERE rno > 1
SELECT * FROM @Widgets
You ought to be able to run all that and get these results in SQL Server:
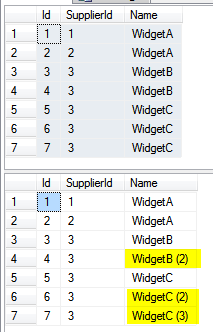
Adapt to your needs :).